Sep 1, 2022
5 min
DALL·E: Introducing Outpainting
Extend creativity and tell a bigger story with DALL-E images of any size Original outpainting by Emma Catnip Today we’re introducing Outpainting, a new feature

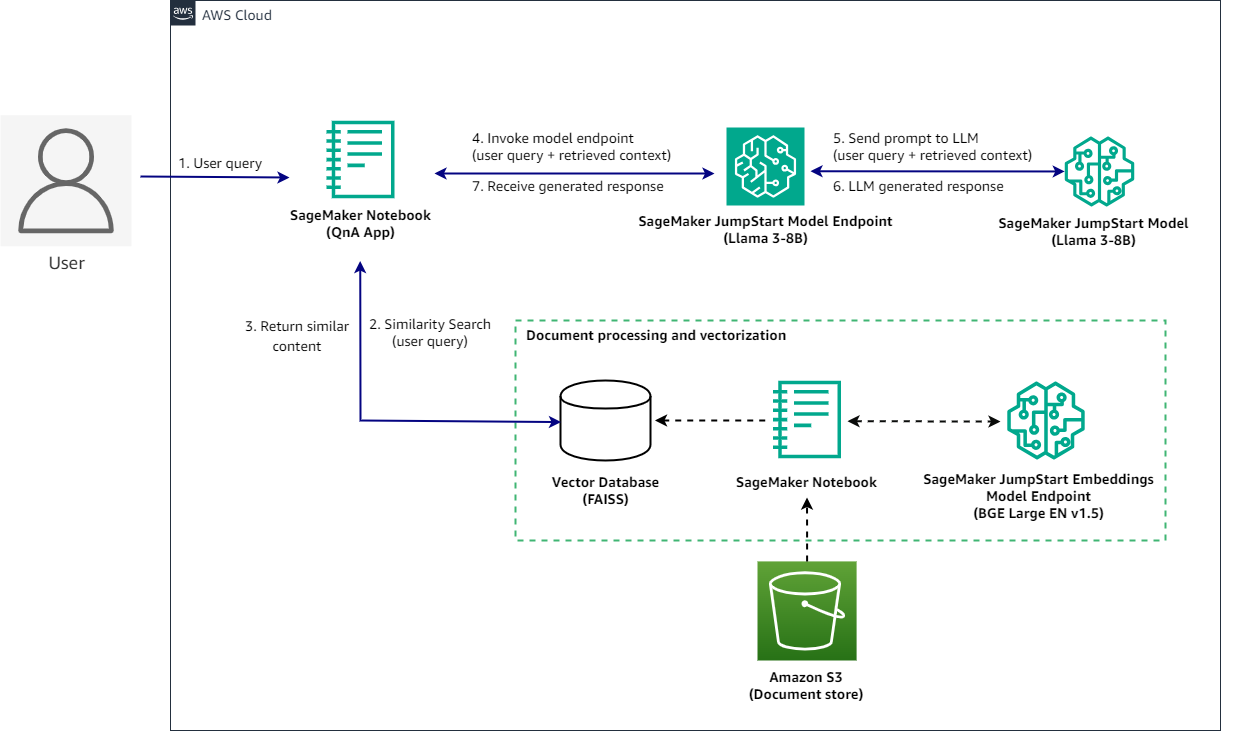
Amazon SageMaker Training Managed Warm Pools gives you the flexibility to opt in to reuse and hold on to the underlying infrastructure for a user-defined period of time. This is done while also maintaining the benefit of passing the undifferentiated heavy lifting of managing compute instances in to Amazon SageMaker Model Training. In this post, we outline the key benefits and pain points addressed by SageMaker Training Managed Warm Pools, as well as benchmarks and best practices.
SageMaker Model Training is a fully managed capability that spins up instances for every job, trains a model, runs and then spins down instances after the job. You’re only billed for the duration of the job down to the second. This fully managed capability gives you the freedom to focus on your machine learning (ML) algorithm and not worry about undifferentiated heavy lifting like infrastructure management while training your models.
This mechanism necessitates a finite startup time for a training job. Although this startup time, also known as cold-start startup time, is fairly low, some of our most demanding customer use cases require even lower startup times, such as under 20 seconds. There are two prominent use cases that have these requirements:
For such use cases, every second spent on overhead, like the startup time for a training job, has a cumulative effect on all these jobs.
With SageMaker Training Managed Warm Pools, data scientists and ML engineers have the ability to opt in to keep SageMaker training instances or multi-instance clusters warm for a prespecified and reconfigurable time (keep_alive_period_in_seconds) after each training job completes. So even though you incur a cold-start penalty for the first training job run on an instance or cluster, for all the subsequent training jobs, the instances are already up and running. As a result, these subsequent training jobs that start on an instance before the keep_alive_period_in_seconds expires don’t incur the cold-start startup time overhead. This can reduce training job startup times to roughly less than 20 seconds (P90).
Data scientists and ML engineers can use SageMaker Training Managed Warm Pools to keep single or multiple instances warm in between training runs for experimentation or run multiple jobs consecutively on the same single or multi-instance cluster. You only pay for the duration of training jobs and the reconfigurable keep_alive_period_in_seconds like everywhere else you specify for every single instance.
In essence, with SageMaker Training Managed Warm Pools, you get a combination of SageMaker managed instance utilization with the ability to opt in and provision capacity and self-manage utilization for short intervals of time. These intervals are configurable before a job, but if during the keep_alive_period_in_seconds interval, you need to reduce or increase it, you can do so. Increases to keep_alive_period_in_seconds can be done in intervals of up to 60 minutes, with a max period for an instance or cluster being 7 days.
To get started with warm pools, first request a warm pool quota limit increase, then specify the keep_alive_period_in_seconds parameter when starting a training job.
We performed benchmarking tests to measure job startup latency using a 1.34 GB TensorFlow image, 2 GB of data, and different training data input modes (Amazon FSx, Fast File Mode, File Mode). The tests were run across a variety of instance types from the m4, c4, m5, and c5 families in the us-east-2 Region. The startup latency was measured as the time of job creation to the start of the actual training job on the instances. The first jobs that started the cluster and created the warm pool had a startup latency of 2–3 minutes. This higher latency is due to the time taken to provision the infrastructure, download the image, and download the data. The consequent jobs that utilized the warm pool cluster had a startup latency of approximately 20 seconds for Fast File Mode (FFM) or Amazon FSx, and 70 seconds for File Mode (FM). This delta is a result of FM requiring the entire dataset to be downloaded from Amazon S3 prior to the start of the job.
Your choice of training data input mode affects the startup time, even with Warm Pools. Guidance on what input mode to select is in the best practices section later in this post.
The following table summarizes the job startup latency P90 for different training data input modes.
Data Input Mode
Startup Latency P90 (seconds)
First Job
Warm Pool Jobs (second job onwards)
FSx
136
19
Fast File Mode
143
21
File Mode
176
70
In the following section, we share some best practices when using warm pools.
Warm pools are recommended in the following scenarios:
Warm pools are not recommended when it’s unlikely that someone will reuse the warm pool before it expires. For example, a single lengthy job that runs via an automated ML pipeline.
Training jobs that reuse a warm pool start faster than the first job that created the warm pool. This is due to keeping the ML instances running between jobs with a cached training container Docker image to skip pulling the container from Amazon Elastic Container Registry (Amazon ECR). However, even when reusing a warm pool, certain initialization steps occur for all jobs. Optimizing these steps can reduce your job startup time (both first and subsequent jobs). Consider the following:
When working with a large team of data scientists, you can share warm pools that have matching job criteria, such as the same AWS Identity and Access Management (IAM) role or container image.
Let’s look at an example timeline. User-1 starts a training job that completes and results in a new warm pool created. When user-2 starts a training job, the job will reuse the existing warm pool, resulting in a fast job startup. While user-2’s job is running with the warm pool in use, if another user starts a training job, then a second warm pool will be created.
This reuse behavior helps reduce costs by sharing warm pools between users that start similar jobs. If you want to avoid sharing warm pools between users, then users’ jobs must not have matching job criteria (for example, they must use a different IAM role).
When using warm pools for experimentation, we recommend notifying users when their job is complete. This allows users to resume experimentation before the warm pool expires or stop the warm pool if it’s no longer needed. You can also automatically trigger notifications through Amazon EventBridge.
With warm pools, you can start a job in less than 20 seconds. Some scenarios require real-time, hands-on interactive experimentation and troubleshooting. The open-source SageMaker SSH Helper library allows you to shell into a SageMaker training container and conduct remote development and debugging.
With SageMaker Training Managed Warm Pools, you can keep your model training hardware instances warm after every job for a specified period. This can reduce the startup latency for a model training job by up to 8x. SageMaker Training Managed Warm Pools are available in all public AWS Regions where SageMaker Model Training is available.
To get started, see Train Using SageMaker Managed Warm Pools.
Dr. Romi Datta is a Senior Manager of Product Management in the Amazon SageMaker team responsible for training, processing and feature store. He has been in AWS for over 4 years, holding several product management leadership roles in SageMaker, S3 and IoT. Prior to AWS he worked in various product management, engineering and operational leadership roles at IBM, Texas Instruments and Nvidia. He has an M.S. and Ph.D. in Electrical and Computer Engineering from the University of Texas at Austin, and an MBA from the University of Chicago Booth School of Business.
 Arun Nagarajan is a Principal Engineer with the Amazon SageMaker team focussing on the Training and MLOps areas. He has been with the SageMaker team from the launch year, enjoyed contributing to different areas in SageMaker including the realtime inference and Model Monitor products. He likes to explore the outdoors in the Pacific Northwest area and climb mountains.
Arun Nagarajan is a Principal Engineer with the Amazon SageMaker team focussing on the Training and MLOps areas. He has been with the SageMaker team from the launch year, enjoyed contributing to different areas in SageMaker including the realtime inference and Model Monitor products. He likes to explore the outdoors in the Pacific Northwest area and climb mountains.
 Amy You is a Software Development Manager at AWS SageMaker. She focuses on bringing together a team of software engineers to build, maintain and develop new capabilities of the SageMaker Training platform that helps customers train their ML models more efficiently and easily. She has a passion for ML and AI technology, especially related to image and vision from her graduate studies. In her spare time, she loves working on music and art with her family.
Amy You is a Software Development Manager at AWS SageMaker. She focuses on bringing together a team of software engineers to build, maintain and develop new capabilities of the SageMaker Training platform that helps customers train their ML models more efficiently and easily. She has a passion for ML and AI technology, especially related to image and vision from her graduate studies. In her spare time, she loves working on music and art with her family.
 Sifei Li is a Software Engineer in Amazon AI where she’s working on building Amazon Machine Learning Platforms and was part of the launch team for Amazon SageMaker. In her spare time, she likes playing music and reading.
Sifei Li is a Software Engineer in Amazon AI where she’s working on building Amazon Machine Learning Platforms and was part of the launch team for Amazon SageMaker. In her spare time, she likes playing music and reading.
 Jenna Zhao is a Software Development Engineer at AWS SageMaker. She is passionate about ML/AI technology and has been focusing on building SageMaker Training platform that enables customers to quickly and easily train machine learning models. Outside of work, she enjoys traveling and spending time with her family.
Jenna Zhao is a Software Development Engineer at AWS SageMaker. She is passionate about ML/AI technology and has been focusing on building SageMaker Training platform that enables customers to quickly and easily train machine learning models. Outside of work, she enjoys traveling and spending time with her family.
 Paras Mehra is a Senior Product Manager at AWS. He is focused on helping build Amazon SageMaker Training and Processing. In his spare time, Paras enjoys spending time with his family and road biking around the Bay Area. You can find him on LinkedIn.
Paras Mehra is a Senior Product Manager at AWS. He is focused on helping build Amazon SageMaker Training and Processing. In his spare time, Paras enjoys spending time with his family and road biking around the Bay Area. You can find him on LinkedIn.
 Gili Nachum is a senior AI/ML Specialist Solutions Architect who works as part of the EMEA Amazon Machine Learning team. Gili is passionate about the challenges of training deep learning models, and how machine learning is changing the world as we know it. In his spare time, Gili enjoy playing table tennis.
Gili Nachum is a senior AI/ML Specialist Solutions Architect who works as part of the EMEA Amazon Machine Learning team. Gili is passionate about the challenges of training deep learning models, and how machine learning is changing the world as we know it. In his spare time, Gili enjoy playing table tennis.
 Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
 Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.Source: Original Article
Last updated: March 23, 2026